Claude Code 에이전트 6개로 숏폼 영상 자동화 파이프라인 만들기
대본 → 장면설계 → 이미지 → 음성 → 영상 → 편집, 전 과정을 AI 에이전트로 자동화한 실전 기록

Claude Code 에이전트 6개로 숏폼 영상 자동화 파이프라인 만들기
대본 → 장면설계 → 이미지 → 음성 → 영상 → 편집, 전 과정을 AI 에이전트로 자동화한 실전 기록
TL;DR
- Claude Code 에이전트 6개로 숏폼 영상 제작 전 과정을 자동화하는 파이프라인 구축
- "대충 돌아가는" 상태에서 실제 제작하며 문제를 하나씩 해결 — 바이브코딩 워크플로우
- AI 이미지 글자 깨짐 방어, 복잡도 기반 A/B 버전 전략, 오디오-영상 길이 자동 보정 등 실전에서 부딪힌 문제 중심 설계
왜 숏폼 파이프라인이 필요했는가
숏폼 영상 하나를 만들려면 생각보다 많은 단계가 필요합니다. 대본을 쓰고, 장면을 설계하고, 이미지를 생성하고, 나레이션 음성을 만들고, 이미지를 영상으로 변환하고, 마지막으로 전부 편집해서 하나의 영상으로 합쳐야 합니다.
이걸 매번 수동으로 하면 한 편에 반나절은 걸립니다. 그래서 Claude Code의 에이전트 시스템으로 각 단계를 자동화하기로 했습니다.
처음엔 "대충 돌아가게만" 만들었는데, 실제로 영상을 만들어보니 곳곳에서 문제가 터졌습니다. 이 글은 그 문제들을 하나씩 해결하면서 파이프라인이 진화한 과정입니다.
파이프라인 전체 구조
최종적으로 완성된 파이프라인은 6개 에이전트가 순차적으로 연결되는 구조입니다.
Writer → Scene Designer → Image Generator → TTS Generator → Video Prompter → Editor
(대본) (장면설계) (이미지생성) (음성생성) (영상프롬프트) (최종편집)
각 에이전트는 이전 에이전트의 출력물을 입력으로 받습니다. Writer가 만든 10문장 스크립트를 Scene Designer가 읽고, Scene Designer가 설계한 장면을 Image Generator가 이미지로 만드는 식입니다.
실제 결과물로 보는 파이프라인
첫 번째 에피소드 "배민 뇌건강" 편의 실제 제작 과정을 따라가 보겠습니다.
Step 1. 대본 — Writer 에이전트
주제와 제목을 주면 10문장 나레이션 스크립트를 생성합니다. 실제로 나온 대본입니다.
1 배달 음식 자주 시켜 드시죠?
2 근데 그게 뇌를 망가뜨리고 있을 수 있어요.
3 초가공식품은 뇌의 기억 중추인 해마 크기를 줄여요.
4 포화지방이 많으면 뇌로 가는 혈류가 막히기 시작해요.
5 혈당이 급격히 오르내리면 집중력이 뚝 떨어져요.
6 반대로 오메가3, 채소가 많은 식단은 뇌 염증을 낮춰줘요.
7 일주일에 배달 2회만 줄여도 차이가 생길 수 있어요.
8 그 자리를 견과류, 생선, 잎채소로 채워보세요.
9 거창하게 식단 바꿀 필요 없어요, 한 끼만 바꿔도 돼요.
10 뇌를 위한 선택, 오늘 저녁 한 끼부터 시작해봐요.
처음에는 "10문장 나레이션을 써줘" 정도의 지시만 있었습니다. 그런데 AI가 반복적으로 같은 실수를 했습니다. 한 번호에 문장을 2개씩 넣거나, "훅 --", "CTA --" 같은 구조 라벨을 나레이션에 섞어 넣거나, 끝에 참고 논문 출처를 덧붙이거나.
이런 실수들이 반복되자, 에이전트에 "절대 금지 사항"을 최우선 규칙으로 올리고, BAD/GOOD 예시를 넣고, 레퍼런스 스크립트 2개를 통째로 넣어서 톤과 길이를 앵커링했습니다.
핵심 교훈: AI에게 "하지 마"라고 말하는 것보다, "이렇게 해"라는 구체적 예시를 보여주는 게 훨씬 효과적이었습니다.
Step 2. 장면 설계 — Scene Designer 에이전트
대본 10문장을 받아서 각 문장에 대한 비주얼, 캐릭터 등장 여부, 카메라, 톤을 설계하고, Gemini 이미지 생성용 영문 프롬프트까지 작성합니다.
세계관은 "종이인형 디오라마" — 모든 것이 종이로 만들어진 세계입니다. 수채화지 질감, 가위로 거칠게 자른 테두리, 겹겹이 종이 레이어로 입체감을 만듭니다.
캐릭터는 "노쭈굴" — 종이인형 캐릭터입니다. 이 캐릭터의 레퍼런스 이미지를 Gemini에 전달해서, 장면마다 일관된 모습으로 등장시킵니다.

노쭈굴 캐릭터 레퍼런스 이미지. Gemini에 전달되는 원본.
실제로 생성된 장면 이미지들입니다.


왼쪽부터: 1번(배달 봉투 산더미), 2번(뇌에 기름 떨어짐), 5번(혈당 롤러코스터)
추상적 개념을 종이인형 세계 안에서 물리적으로 표현하는 게 이 파이프라인의 재미있는 부분입니다. 혈당 변화 → 롤러코스터, 호르몬 → 반짝이, 망가짐 → 종이가 구겨짐, 회복 → 팝업북이 펼쳐짐.
추가 공정 1: 장면 체이닝 — 같은 오브젝트의 시각적 일관성
장면설계에서 가장 큰 문제는 시각적 일관성이었습니다.
예를 들어 "뇌"가 2번 장면에서 처음 등장하고 6번에서 다시 나옵니다. 각 장면의 이미지를 독립적으로 생성하면, 2번의 뇌와 6번의 뇌가 완전히 다른 모양이 됩니다. 시청자 입장에서는 같은 영상 안에서 뇌가 매번 바뀌니 어색합니다.
이 문제를 해결하기 위해 "장면 체이닝" 시스템을 만들었습니다.
뇌: ② (첫등장, 기름) → ⑥ (회복)
배달봉투: ① (첫등장) → ⑦ (떼기)
노쭈굴: ⑦ (첫등장) → ⑧ → ⑩
같은 오브젝트가 처음 등장한 장면의 생성 결과물을 다음 장면의 레퍼런스 이미지로 전달합니다. 실제로 6번 장면을 생성할 때 2번 장면의 이미지를 --references로 넘기고, 프롬프트에 "The same paper brain from the reference, but now uncrumpling"이라고 명시합니다.
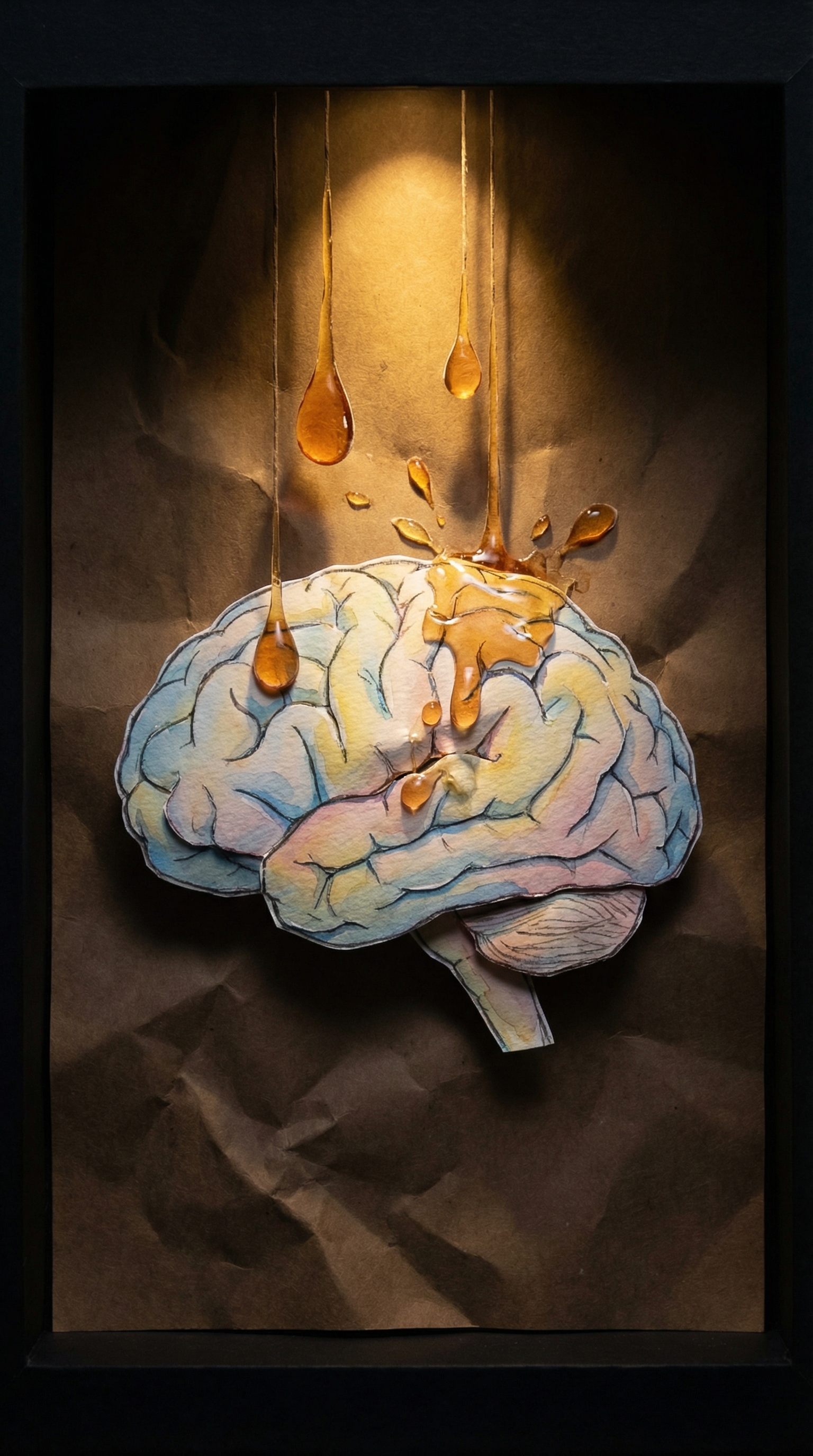
아래는 체이닝의 실제 결과입니다. 2번(기름에 망가진 뇌)과 6번(회복된 뇌)의 뇌 형태가 일관되게 유지됩니다.
2번 — 기름에 구겨지는 뇌 (소스)

6번 — 회복되는 뇌 (타겟)
체이닝이 있으면 이미지 생성 순서도 달라집니다. 6번을 만들려면 2번이 먼저 있어야 하고, 7번을 만들려면 1번이 먼저 있어야 합니다. 그래서 장면설계 문서 상단에 체이닝 맵과 생성 순서를 명시하도록 했습니다.
생성 순서: ① → ② → ③ → ④ → ⑤ → ⑥(←②) → ⑦(←①) → ⑧(←⑦) → ⑨ → ⑩(←⑧)
추가 공정 2: AI 이미지의 글자 문제 — 3단계 방어
AI 이미지 생성에서 가장 흔하고 짜증나는 문제입니다. 분명 글자를 넣으라고 안 했는데, 이미지에 알 수 없는 문자가 적혀 있습니다.
실제로 9번 장면에서 이 문제가 발생했습니다.

9번 장면 — "거창하게 식단 바꿀 필요 없어요". 식단표 찢어지는 장면인데, "ELABORATE MEAL PLAN"이라는 영문 텍스트가 들어가 버렸음. 프롬프트에 "meal plan chart"라고만 썼는데 AI가 알아서 글자를 넣음.
이 문제에 3단계 방어를 설계했습니다.
1단계 — 예방: 캘린더, 음식 패키지, 간판이 등장하는 장면은 첫 생성부터 프롬프트에 No text, no labels, no words, no letters, no writing anywhere.를 추가합니다.
2단계 — 감지: 매 장면 생성 후 반드시 이미지를 열어서 시각적으로 확인합니다. 확인 없이 다음으로 넘어가지 않습니다.
3단계 — 재생성: 글자가 발견되면 anti-text 프롬프트를 강화해서 재생성합니다. 최대 2회 재시도하고, 3회 실패하면 스킵하고 실패 목록에 기록합니다.
Step 3. 이미지 생성 — Image Generator 에이전트
장면설계 문서의 실행 커맨드를 순차적으로 실행합니다. 체이닝 의존성 때문에 병렬 생성은 하지 않습니다. 실제 실행 커맨드는 이렇게 생겼습니다.
# 7번 장면: 노쭈굴 캐릭터 + 1번 장면의 배달봉투를 레퍼런스로 전달
python generate.py generate \
--prompt "A whimsical, three-dimensional diorama scene..." \
--references "nojjugul_front.png,scene_01.png" \
--output "scene_07.png" \
--aspect-ratio 9:16 --size 2K --model pro
캐릭터가 등장하는 장면에서는 레퍼런스 이미지를 2개 이상 전달합니다 — 캐릭터 원본 + 체이닝 소스. 아래는 실제 결과입니다.

7번 — 캐릭터가 배달봉투 떼기

10번 — 캐릭터가 직접 요리
Step 4. 음성 생성 — TTS Generator 에이전트
Typecast API로 10문장의 나레이션 음성을 생성합니다. 여기서 중요한 추가 공정이 감정 자동 설계입니다.
처음에는 전부 같은 톤으로 TTS를 돌렸습니다. 밋밋했습니다. 그래서 문장의 위치와 내용에 따라 감정 프리셋을 자동으로 매핑하는 규칙을 만들었습니다.
실제 "배민 뇌건강" 에피소드의 감정 설계입니다.
| # | 대사 | 감정 | 이유 |
|---|---|---|---|
| 01 | 배달 음식 자주 시켜 드시죠? | normal | 자연스러운 말걸기 |
| 02 | 근데 그게 뇌를 망가뜨리고 있을 수 있어요. | tonedown | 무게감, 긴장 |
| 03~05 | 과학 설명 | normal | 담담한 정보 전달 |
| 06 | 반대로 오메가3... | toneup | 분위기 반전 |
| 07~09 | 해결책 | happy (0.7) | 부드러운 격려 |
| 10 | 마무리 | happy (1.0) | 마무리 에너지 |
그리고 TTS 생성 후 자동으로 오디오 리포트가 만들어집니다. 각 문장의 초 단위 길이가 기록됩니다.
01: 1.9초 | 02: 2.6초 | 03: 3.4초 | 04: 3.3초 | 05: 3.1초
06: 3.2초 | 07: 3.1초 | 08: 3.0초 | 09: 2.8초 | 10: 2.9초
총 길이: 29.4초
이 리포트가 왜 중요한지는 다음 단계에서 드러납니다.
Step 5. 영상 프롬프트 — Video Prompter 에이전트
Veo API로 이미지를 영상으로 변환하기 위한 프롬프트를 작성합니다. 여기서 두 가지 핵심 추가 공정이 들어갑니다.
추가 공정 3: 복잡도 기반 모델 선택과 A/B 버전
Veo로 이미지를 영상으로 변환할 때, 단순한 장면은 잘 되는데 복잡한 장면은 자주 실패했습니다. 스타일이 깨지거나, 동작이 의도와 완전히 달라지거나.
그래서 각 장면의 이미지 복잡도를 분석해서 전략을 다르게 가져갑니다.
| 위험도 | 기준 | 전략 |
|---|---|---|
| 낮음 | 오브젝트 1~2개, 단순 카메라 | Fast 모델 1버전 |
| 중간 | 오브젝트 3~4개, 중간 움직임 | Fast 먼저, 실패 시 Standard |
| 높음 | 오브젝트 5개+, 캐릭터+소품 동시 동작 | A(Standard) + B(Fast) 2버전 동시 생성 |
위험도가 높은 장면은 2가지 버전을 만들어서 직접 비교하고 선택합니다.
실제로 7번 장면(캐릭터+캘린더+봉투+꽃)과 10번 장면(캐릭터+부엌+냄비+뇌+꽃잎)에서 A/B 버전이 생성되었습니다.
7번 장면 A/B 비교:
왼쪽 A(Standard): 캐릭터가 봉투를 떼고 꽃이 피는 상세한 동작 / 오른쪽 B(Fast): 미세한 움직임만. 비교해서 택 1.
비용도 다릅니다. Standard는 초당 $0.40, Fast는 $0.15. 단순한 장면에 Standard를 쓰면 돈 낭비입니다. 복잡도 분석이 비용 최적화도 해줍니다.
3번 장면 — 첫 시도(실패) vs 재생성:
왼쪽: 첫 시도(실패) / 가운데: Standard 재생성 / 오른쪽: Simple 재생성
추가 공정 4: 영상 Duration과 나레이션 길이 맞추기
Veo API는 4초, 6초, 8초 세 가지 길이만 지원합니다. 실제 나레이션은 1.9초, 3.4초 등 제각각입니다.
이 문제를 2단계에 걸쳐 해결합니다.
1단계 (Video Prompter): 오디오 리포트에서 각 문장의 초 단위 길이를 읽고, 가장 가까운 Veo 옵션을 선택합니다. 이 에피소드에서는 최장 나레이션이 3.4초여서 전부 4초로 결정되었습니다.
2단계 (Editor): 생성된 영상의 재생 속도를 오디오 길이에 맞게 자동 조절합니다.
speed = 영상길이(4초) / 오디오길이(1.9초) = 2.1배속
ffmpeg -filter:v "setpts=PTS/2.1"
4초 영상에 1.9초 오디오면 약 2배속으로 빠르게 돌립니다. 종이인형 디오라마 스타일이라 약간 빨라져도 자연스럽습니다.
대충 했으면 4초 영상에 1.9초 나레이션이 붙고 나머지 2초는 묵음이거나, 영상이 먼저 끝나거나 했을 겁니다.
Step 6. 최종 편집 — Editor 에이전트
모든 재료가 모이면 Editor 에이전트가 5단계 파이프라인으로 최종 영상을 만듭니다.
무음 트림 → 0.5초 패딩 삽입 → 영상 속도 조절 머지 → 전체 이어붙이기 → 자막 번인
- 무음 트림: TTS가 만든 음성 앞뒤의 불필요한 무음을 제거합니다. -40dB 기준.
- 패딩 삽입: 문장 사이에 0.5초 무음을 넣어서 호흡을 줍니다. 마지막 문장은 패딩 없이.
- 영상 속도 조절: 위에서 설명한 대로, 오디오 길이에 맞춰 영상 속도를 자동 조절합니다.
- 자막 번인: ASS 포맷으로 자막을 생성해서 영상에 굽습니다. Pretendard Bold 44pt, 하단 중앙. 여기서
MarginV=280이라는 값이 중요한데, 숏폼 앱의 좋아요/댓글 버튼과 겹치지 않도록 올린 값입니다. 실제로 겹치는 걸 보고 조정했습니다.
아래는 자막이 번인된 최종 결과물의 한 프레임입니다.

자막이 번인된 최종 영상 프레임. 하단에 자막이 위치하되, 숏폼 앱 UI와 겹치지 않는 높이.
최종 완성 영상 (자막 포함):
최종 결과:
총 길이: 약 35초
출력 파일:
- full.mp4 (자막 없음)
- full_sub.mp4 (자막 포함)
- subs.ass (자막 파일)
에이전트 간 데이터 연결이 핵심이었다
돌이켜보면, 개별 에이전트의 품질보다 에이전트 간 데이터가 어떻게 흘러가는지가 더 중요했습니다.
- TTS Generator가 오디오 리포트(초 단위 길이)를 남기지 않으면, Video Prompter가 duration을 결정할 수 없습니다
- Scene Designer가 체이닝 맵을 문서에 명시하지 않으면, Image Generator가 생성 순서를 판단할 수 없습니다
- Editor가 영상 소스 우선순위(final/ → drafts/ 폴백)가 없으면, 매번 파일을 수동으로 옮겨야 합니다
각 에이전트가 "다음 에이전트가 뭘 필요로 하는지"를 알고 그에 맞는 출력물을 남기는 구조. 이게 파이프라인의 진짜 설계 포인트였습니다.
실제 프로젝트 폴더 구조가 이 연결을 보여줍니다.
episodes/001_배민_뇌건강/
├── scripts/ ← Writer 출력
├── docs/ ← Scene Designer 출력 (장면설계, 영상프롬프트)
├── images/ ← Image Generator 출력 (scene_01~10.png)
├── audio/ ← TTS Generator 출력
│ ├── 01_배달 음식 자주 시켜 드시죠.mp3
│ ├── trimmed/ ← Editor가 자동 생성
│ └── padded/ ← Editor가 자동 생성
└── video/
├── drafts/ ← Video Prompter 출력 (A/B 버전 포함)
├── final/ ← 유저가 확정한 영상
└── merged/ ← Editor 최종 출력
추가 공정 요약: 대충 했을 때 vs 지금
| 단계 | 대충 했을 때 | 추가된 품질 공정 |
|---|---|---|
| 대본 | 그냥 10문장 | 한 번호 한 문장 강제, 메타라벨/출처 금지, 레퍼런스 앵커링 |
| 장면설계 | 독립적 이미지 | 체이닝 시스템, 글자 금지, 톤 감정곡선, 시각적 메타포 가이드 |
| 이미지생성 | 커맨드 10개 실행 | 순차 실행, 글자 3단계 방어, 매 장면 시각 확인, venv 경로 고정 |
| 음성생성 | 전부 같은 감정 | 감정 자동 설계, 오디오 리포트 자동 생성, rate limit 재시도 |
| 영상프롬프트 | 전부 Standard | 복잡도 3단계 분석, A/B 버전 전략, duration 매핑, 비용 최적화 |
| 편집 | 그냥 concat | 무음트림 → 패딩 → 속도조절 → concat → 자막번인 5단계 |
배운 것
바이브코딩 관점
"대충 돌아가게 먼저 만들고, 문제를 만나면 고친다"가 에이전트 설계에서도 통했습니다. 처음부터 완벽한 에이전트를 설계하려 하면 실제로 안 쓰는 규칙만 잔뜩 넣게 됩니다. 실제로 문제를 겪고 나서 추가한 규칙이 살아남습니다.
에이전트의 "절대 금지" 규칙은 전부 실패 경험에서 나왔습니다. Writer의 "한 번호에 한 문장만", Image Generator의 "글자 방지 3단계"는 모두 실제로 그 실수가 반복된 후에 추가된 것들입니다.
에이전트 간 인터페이스(출력 포맷)가 개별 에이전트 품질보다 중요했습니다. 오디오 리포트의 포맷이 바뀌면 Video Prompter가 깨지고, 체이닝 맵의 포맷이 바뀌면 Image Generator가 깨집니다. 에이전트를 하나씩 개선하는 것보다 이 연결 지점을 안정화하는 게 먼저였습니다.
개발 관점
- AI 이미지의 글자 문제는 "넣지 마"로 안 됩니다. 예방(프롬프트) + 감지(시각 확인) + 재생성의 3단계가 필요합니다.
- Veo의 duration이 4/6/8초 고정이라는 제약은 ffmpeg 속도 조절로 우회할 수 있습니다. 종이인형 스타일처럼 약간의 속도 변화가 자연스러운 아트 스타일이면 특히 효과적입니다.
- Rate limit 관리는 에이전트에 내장해야 합니다. Typecast, Gemini, Veo 모두 rate limit이 다르고, "동시 10개 가능"이라고 적혀 있어도 실제로는 3개가 안전한 경우가 있었습니다. 문서의 스펙과 실제 안전 한도는 다릅니다.
다음 단계
현재 파이프라인은 에이전트를 하나씩 순차적으로 실행합니다. 다음 목표는 의존성이 없는 단계(예: TTS와 Image Generation)를 병렬로 실행하는 것, 그리고 전체 파이프라인을 하나의 명령으로 돌릴 수 있는 오케스트레이터를 만드는 것입니다.